

ReLOC: Pairwise registration by local orientation cues
The majority of 3D sensors used to acquire shape information, such as laser scanners, stereo and time-of-flight cameras, structured light systems, share the inability to scan the entire object at once. Indeed, a single acquisition captures only the portion of the object seen from the viewpoint of the sensor. This issue can be dealt with by acquiring the object from different vantage points so to cover the entire surface. As each acquisition is represented with respect to a reference frame centered in the sensor, multiple acquisitions have to be aligned in a unique and common reference frame. Such process takes the name of 3D Registration and is typically solved by aligning, in the first place, the partial views in pairs.
Usually, this problem, referred to as Pairwise registration, is faced by extracting a set of feature points from the two views and the local neighbourhood of each point is projected onto a suitable high-dimensional feature space so as to obtain a description invariant (or covariant) to pose and as robust as possible to the nuisances induced by acquisition. Then, correspondences between local features are established based on similarities of descriptions, so that, eventually, the rigid motion that best aligns corresponding feature points is easily computed by a robust estimator, such as e.g. RANSAC. The most widespread approach to attain pose invariance deploys a Local Reference Frame (LRF) centered on the feature point and attached to the surface regardless of its orientation. Thereby, description can encode local shape traits with respect to a canonical reference associated with the feature point. Although effective and fast algorithms pertaining their computation have been devised in the field of registration LRFs have so far only been considered instrumental to feature description.
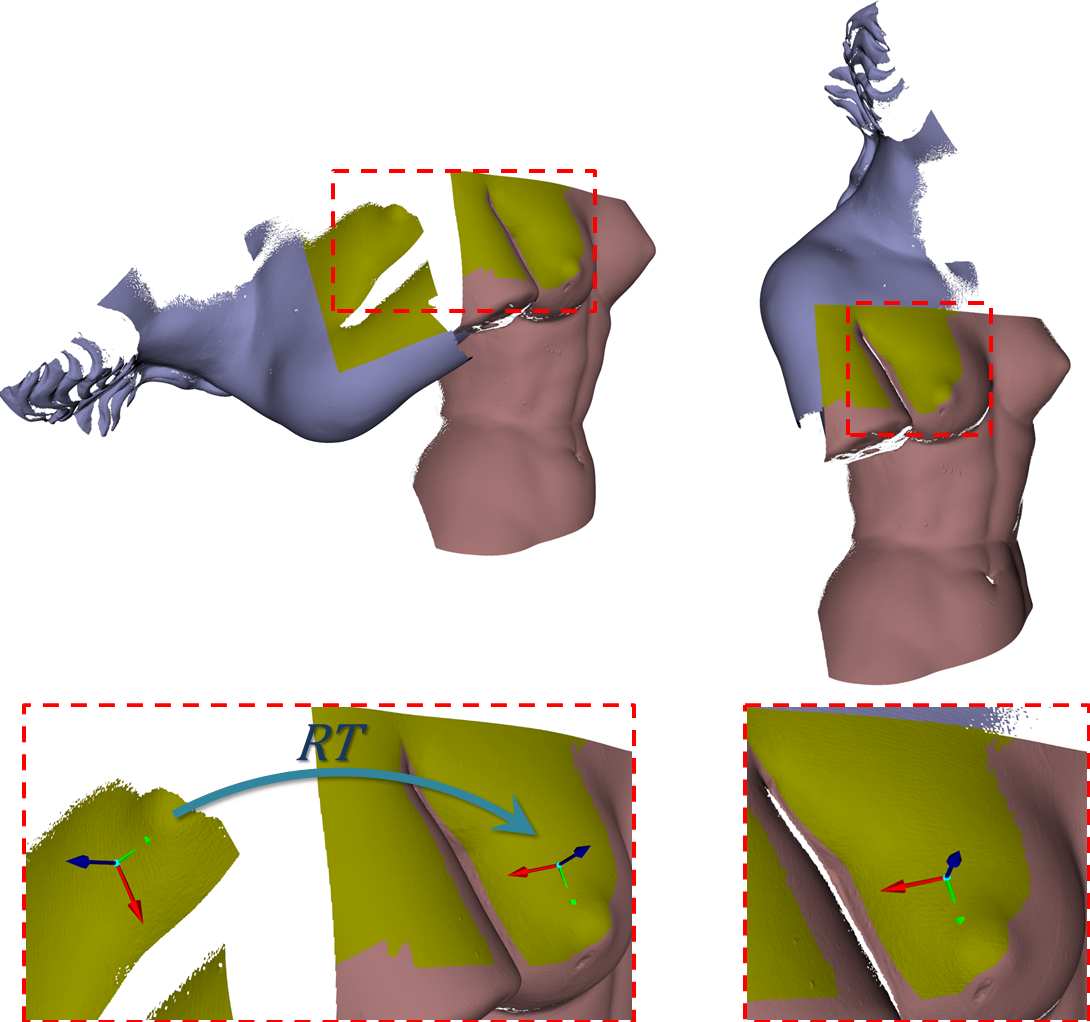
Conversely, ReLOC algorithm grounds on a different and novel registration paradigm, which stems from the observations that LRFs can indeed provide basic shape cues and that two corresponding points equipped with their LRFs allows the rigid motion that aligns two views to be computed. More precisely, we rely on the FLARE method proposed in [2] to compute highly repeatable LRFs at feature points and show how such computation provides the core of a coarse registration pipeline which does not require a costly feature description stage.
Therefore, the algorithm prunes false correspondences by enforcing geometric consistency constraints according to the Hough Voting method proposed in [3], which, again, relies on the availability of repeatable LRFs attached to features.
Although ReLOC can be feed with any kind of 3D feature points, a novel detector specifically conceived to provide features suited to the method is proposed. In particular, it relies on the assumption that underling saliency cue should capture the orientability of features, i.e. the ability to compute the LRF repeatably despite feature localization being possibly inaccurate. Accordingly, ReLOC deploys an efficient detector which conveniently exploits the observed relationship between orientability and flatness to quickly extract features particularly suitable for the pipeline and uniformly distributed throughout the views, the latter being a beneficial property for coarse registration.
The C++ source code of the algorithm can be found here.
Experimental Evaluation
The quantitative results of the benchmark described in [1] can be reproduced by applying the C++ framework provided here.
Note: The obtained results turn out slightly different from those reported in the paper as the implementations of the detector and RANSAC provided here rely on a different random number generator.
Full 3D Reconstructions
Based on the pairwise registrations provided by the algorithm, the framework described in [4] is exploited to get a global, though coarse, reconstruction by determining a spanning tree where the edges join the view pairs that maximize the overlap area. This process is applied to two datasets acquired by a Kinect sensor (on the left in the figure) and to two cultural heritage objects acquired by a high-precision laser scanner (the Venus and Shell on the right in the figure). Due to both the acquisition quality of the Venus and Shell datasets and the accuracy of the algorithm, the views come out finely aligned, even though no ICP-based fine registration is run downstream. Conversely, for the kinect datasets, the Scanalyze tool is run to get a global refinement of the registration and the Poisson Reconstruction algorithm [5] to obtain the final 3D models.

References
| [1] | Petrelli A., Di Stefano L., "Pairwise registration by local orientation cues", Computer Graphics Forum, 2015. [PDF] |
| [2] | Petrelli A., Di Stefano L., "A repeatable and efficient canonical reference for surface matching", 3DimPvt, 2012. [PDF] |
| [3] | Tombari F., Di Stefano L. "Object recognition in 3d scenes with occlusions and clutter by hough voting" Fourth Pacific-Rim Symposium on Image and Video Technology, 2010, 349–355. |
| [4] | Bariya P., Novatnack J., Schwartz G., Nishino K., "3D Geometric Scale Variability in Range Images: Features and Descriptors", International Journal of Computer Vision 99, 2, 2012. |
| [5] | Kazhdan M., Bolitho M., Hoppe H., "Poisson surface reconstruction", Eurographics Symposium on Geometry Processing, 2006. |
© 2015 The Authors Computer Graphics Forum © 2015 The Eurographics Association and John Wiley & Sons Ltd.