

HyperRGBD: a framework for aggregation of RGB-D datasets
Although a few relatively large RGB-D datasets are available nowadays, their size is far smaller than that of state-of-the-art RGB datasets. To facilitate experimentation with larger and diverse datasets, the HyperRGBD software framework, introduced in [1], allows researchers to create straightforwardly new data with desired traits and peculiarities by mixing arbitrarily and seamlessly images drawn from different RGB-D datasets. HyperRGBD supports the main existing RGB-D datasets for category and instance recognition and provides a standardized open interface to allow integration of upcoming ones.
HyperRGBD is a C++ software framework devised to enable researchers and practitioners to build effortlessly new datasets by aggregating images from different existing RGB-D datasets. For example, one might wish to experiment with datasets larger than existing ones, which would seamlessly be attainable by deploying HyperRGBD to aggregate the images belonging to existing datasets into a larger data corpus. Furthermore, should a dataset be biased towards certain abundant categories with others featuring a few samples only, it would be just as seamless to build a more balanced dataset by using HyperRGBD to draw samples for the rare categories from other datasets. Another example may deal with changing the granularity of categories, e.g. aggregating "chair", "table" and "couch" into a broader "furniture" category or splitting "fruit" into more specific categories like "apple", "orange" and "banana".
At present, we have integrated in the framework the main existing RGB-D datasets for object recognition, i.e. Washington, CIN 2D+3D, BigBIRD and MV-RED. Nonetheless, it is worth pointing out that, indeed, the framework is not confined to the aggregation of RGB-D data only, but it may be exploited to merge any dataset dealing with image recognition.
- Washington: Introduced in [2], the Washington dataset is composed by 41,877 RGB-D images and 300 household objects belonging to 51 categories according to the WordNet hierarchy. For the instance recognition task, the evaluation is performed by applying the Alternating Contiguous Frames methodology and, as suggested in [2], for both category and instance recognition tasks, results are reported by averaging the recognition rates obtained over 10 randomly defined trials.
- CIN 2D+3D [3]: The dataset is partitioned in 18 categories including about 10 instances each. The objects have been acquired by a Kinect sensor from 36 vantage points by rotating a turntable by 10° upon each acquisition. For the evaluation, in the case of category recognition, a tenth of the instances for each category is used as test set and the training of the architecture is performed on the remaining ones. Such procedure is repeated 10 times on different randomly generated test sets so to finally average the obtained recognition rates. 10 trials are also run in case of instance recognition experiments, each trial gathering a different tenth of the views of each instance so as to define the test set. Training is carried out on the remaining views.
- BigBIRD [4]: It consists of supermarket objects acquired by PrimeSense Carmine sensors. The setup staged by the authors involves acquisition from 5 different vantage points of objects placed on a turntable rotating by a 3° step. Thus, 600 views have been acquired for each instance. Again, we adopt the evaluation procedure defined in [38]: first, we apply a cropping procedure to all images to discard the excessive background regions. Then, due to segmentation masks being not reliable for some transparent objects, we discard such objects so to end up with 114 instances. The evaluation is performed over 10 trials by randomly selecting 100 acquisitions for each instance. These are subsequently split to test the methods on a tenth of them after training has been performed on the others.
- MV-RED: Introduced in the 3D Object Retrieval with Multimodal Views track of SHREC 2015, the MV-RED [5] dataset is aimed at 3D model retrieval, each query consisting of all the views of an object instance. It includes 505 different objects acquired from 73 vantage points by a Kinect sensor. As the dataset has been devised to enable retrieval of specific object instances, we partitioned the objects into 96 categories, so to allow its usage in category recognition experiments too. Similarly to BigBIRD, as the sensor is quite far from the turntable, images show exceedingly large uninformative background regions around each object. Moreover, the dataset comprises several small objects, as e.g. "dry_battery", "garlic" and "pills". Accordingly, we applied the same “closing-up” procedure as done with BigBIRD to get smaller images mostly covered by object. For both category and instance recognition, we split the dataset by following the same methodology used with CIN 2D+3D: across 10 trials, we test the methods on a randomly-split tenth of the dataset and perform training on the remaining portion.
As described in [1], we exploited HyperRGBD to obtain two new RGB-D datasets used in our experiments besides the main existing ones:
- HyperRGBD merges all the images of the four datasets. Accordingly, the dataset includes 152,576 images from 1072 different objects when deployed in instance recognition experiments, whereas 84,176 images are divided into 98 categories to pursue category recognition (BigBIRD does not contribute to the data used for category recognition as its objects are not partitioned into categories).
- HyperRGBD - Balanced addresses the wide differences in size between existing datasets by balancing them upon aggregation. More precisely, for instance recognition scenario, we identify the dataset with the fewest instances (BigBIRD comprising 114 instances) and level down the others by randomly selecting 114 instances per dataset. In the case of category recognition, instead, for each of the 98 categories of the aggregated dataset, we search for the dataset providing the smallest amount of instances and, accordingly, populate the category by randomly selecting that amount of instances from each dataset. The resulting dataset comprises about 70,000 images when applied to instance recognition and 90,000 images in the case of category recognition task. Once the datasets are gathered, the training and test set are split following the procedure adopted for CIN 2D+3D and MV-RED as explained in [1].
How it works
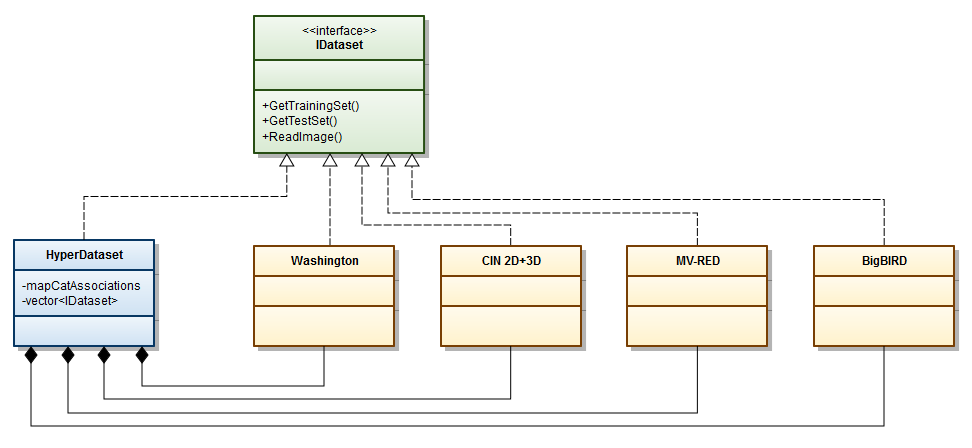
The integration of an existing dataset into the framework is easily accomplished by instantiating a software component featuring a standard interface, referred to as IDataset. This requires the implementation of a few functions:
- ReadImage loads from disk an image in the required format (e.g. RGB, depth map, 3D point cloud, mask image etc.).
- GetTrainingSet returns the training set as a list of images, each one denoted by the associated filename and label.
- GetTestSet returns the test set as a list of images, each one denoted by the associated filename and label.
The aggregation of datasets into new ones is enabled by the HyperDataset component, that, in turn, implements the interface IDataset so to handle any newly created dataset as seamlessly as any other already integrated one. As every dataset partitions its images in different categories, merging different datasets requires to establish a mapping between the categories of the existing datasets and those of the aggregated one. As an example, categories "coffee_mug", "Cup" and "cup" of the Washington, CIN 2D+3D and MV-RED datasets could be mapped into category "cups" of the aggregated dataset. To define and realize such mappings, HyperRGBD defines a convenient standard methodology together with the associated software tools. Once the required mappings are established for the existing datasets through the mapCatAssociations map, HyperDataset will automatically perform the aggregation of the datasets listed in vector<IDataset>. Finally, through suitable components, the user can arbitrarily and easily define different criteria for splitting the resulting dataset in training and test set.
Download
The source code can be downloaded from here. The framework requires the OpenCV library for handling images. Moreover, depth maps and calibration data of BigBIRD dataset are stored in HDF5 format.
Reference
[1] A. Petrelli, L. Di Stefano, "Learning to Weight Color And Depth for RGB-D Image Search" Submitted at International Conference on Image Analysis and Processing (2017).
[2] K. Lai, L. Bo, X. Ren, D. Fox, "A large-scale hierarchical multi-view rgb-d object dataset" International Conference on Robotics and Automation 1817–1824 (2011).
[3] B. Browatzki, J. Fischer, "Going into depth: Evaluating 2D and 3D cues for object classification on a new, large-scale object dataset" International Conference on Computer Vision Workshops (2011).
[4] A. Singh, J. Sha, K.S. Narayan, T. Achim, P. Abbeel, "BigBIRD: A large-scale 3D database of object instances" International Conference on Robotics and Automation 509–516 (2014).
[5] A. Liu, Z. Wang, W. Nie, Y. Su, "Graph-based characteristic view set extraction and matching for 3D model retrieval" Information Sciences 320, 429–442 (2015).